
缓存概览
缓存的收益:
- 加速读写,优化用户体验
- 降低后端负载
缓存的成本:
- 数据可能无法保证一致性
- 架构复杂度增大
- 代码维护成本(运维成本)增大
适用场景:
- 开销大的复杂计算
- 加速请求响应
缓存穿透及优化
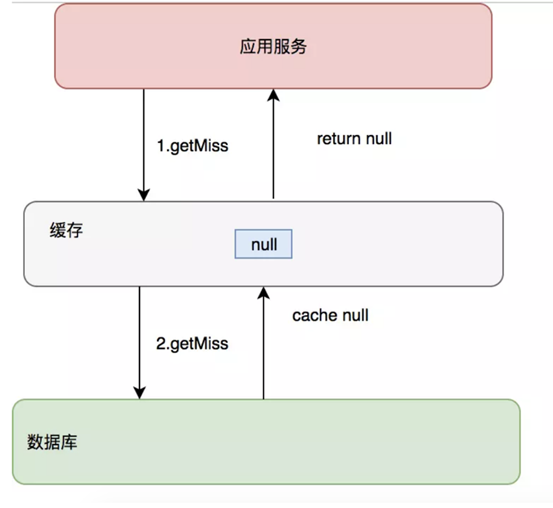
缓存穿透:查询一个根本不存在的数据,缓存层和存储层都不会命中
缓存穿透导致不存在的数据每次请求都要到存储层查询,缓存的保护失去了意义,会使后端存储负载加大
解决办法
-
缓存空对象:存储层不命中后,将空对象保存至缓存层中,之后的访问都会从缓存层获取,这样就保护了后端数据
缺点:
- 缓存空对象,意味着缓存中存了更多的键,会占用空间,可以通过设置过期时间解决
- 缓存层和存储层会有一段时间窗口的不一致(比如缓存层中存了空对象并设置过期时间为5分钟,但此时存储层刚好添加了该键对应的数据,就造成了数据不一致),可以使用消息系统或者其他方式解决
-
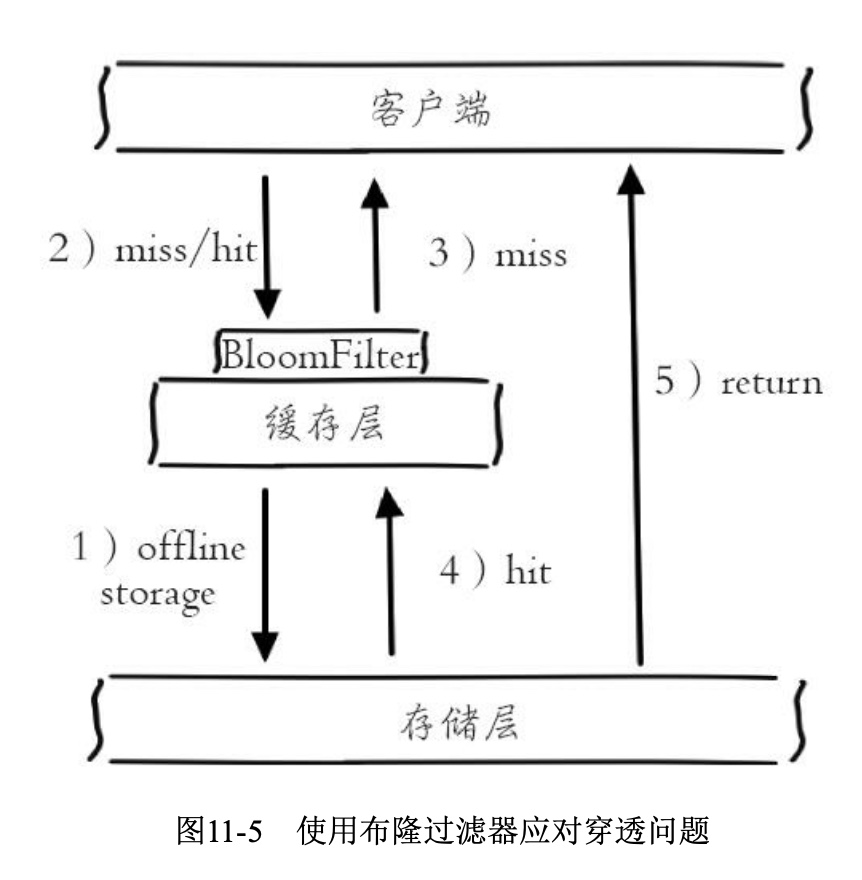
布隆过滤器拦截:缓存穿透是查询一个根本不存在的数据,因此可以在缓存层前加一个布隆过滤器,将不存在的数据拦截。
关于布隆过滤器,可以查看我写的另一篇文章:布隆过滤器的简单总结
两种解决方式的对比
| 解决方式 | 适用场景 | 代价 |
|---|---|---|
| 缓存空对象 | 数据命中不高、数据变化频繁(实时性高) | 需要过多缓存空间、数据不一致 |
| 布隆过滤器 | 数据命中不高,数据相对固定(实时性低) | 代码维护复杂 |
PS:布隆过滤器不适用于数据变化频繁的场景(因为要不停地进行数据的插入和删除,而布隆过滤器对于删除操作极不友好),比较适用于数据相对固定的场景
缓存击穿及优化
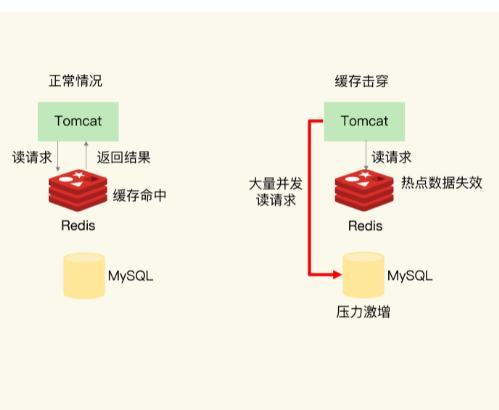
缓存层的某个key承受着非常高的并发,当这个key失效的瞬间,大量的请求会同时击穿缓存,打到DB,就像在纱窗上戳破了一个洞
解决方法
- 设置热点数据不过期,这里的不过期是指物理上的不过期。我们可以设置一个逻辑过期时间,当超过逻辑过期时间时,异步地加载数据,更新缓存。这种方法适用于比较极端的场景(流量特别大),需要承受数据不一致的代价(缓存重构需要时间)
- 给访问DB操作加上互斥锁,只有一个线程能拿到锁,请求DB并把数据刷到缓存中,其他线程再从缓存拿这个数据
两种解决方法的对比
| 解决方法 | 优点 | 缺点 |
|---|---|---|
| 简单分布式锁 | 思路简单、保证一致性 | 代码复杂度大、存在死锁和线程池阻塞的风险 |
| 热点数据永不过期 | 杜绝缓存击穿问题 | 不保证一致性、代码维护成本和内存成本增加 |
缓存雪崩及优化
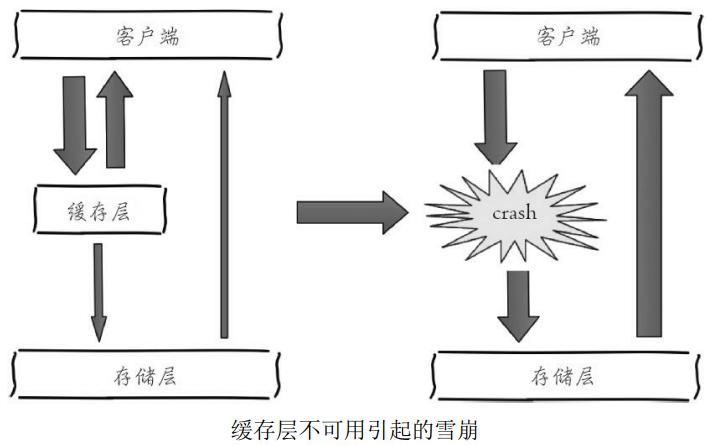
缓存层因为某些原因无法提供服务(比如缓存服务器重启,或者大量key在同一时间失效等情况),所有请求都打到存储层,则存储层的调用量会暴增,造成存储层也级联宕机的情况
针对两种情况,有不同的解决方法
- 缓存层宕机的解决方法:
- 保证缓存层服务高可用,例如使用Redis Sentinel或者Redis Cluster
- 使用隔离组件为后端限流并降级:限制存储层的访问流量(服务限流),并主动停掉一些不太重要的业务,减轻存储层的压力(服务降级)
- 大量key在同一时间失效的解决方法:
- 在原有的失效时间基础上增加一个随机值,防止大批key在同一时刻失效
- 若缓存层是分布式存储,可以将热点数据均匀分布在不同的库中
- 设置热点数据永不过期(如上文所说,需要承受数据不一致的代价)